Denoising without scrubbing the voice
Decades-old lectures arrive with tape hiss, hum, and static. The hard part is not removing the noise — it is removing the noise without eating the voice, gating pauses to dead silence, or inventing sound that was never there.
The lectures we serve were recorded on cassette and reel-to-reel decades ago, in temple rooms and on the road. They carry their age: a steady tape hiss, mains hum, the static of a cheap microphone. Cleaning that up sounds like a solved problem — run a denoiser. The trouble is that a denoiser aggressive enough to erase the hiss is usually aggressive enough to erase part of the voice with it, to gate the pauses into an unnatural vacuum, or — with the newest learned models — to invent audio that was never spoken.
So our rule for cleaning is the same as our rule for everything else: fidelity to the source first. Lower the noise, never maim the voice, and never throw the original away.
How a recording gets cleaned
A noisy recording goes in, a clean one comes out. In between, the cleaner picks a strategy to fit the material, runs it, evens out the loudness, and re-encodes to a canonical mono 128 kbps MP3.
flowchart TD
IN["Noisy recording"] --> STR{"Pick a strategy"}
STR -->|afftdn| A["FFT noise reduction"]
STR -->|"rnnoise-mix"| R["RNNoise + voice-probability blend"]
STR -->|deepfilternet| D["DeepFilterNet3 (learned)"]
A --> NORM["Loudness normalise"]
R --> NORM
D --> NORM
NORM --> OUT["Clean recording"]
Five strategies, one principle
There is no single denoiser. There are five selectable strategies, each a different point on the trade-off between how much noise comes out and how much of the recording survives.
| Strategy | What it is | What it gives |
|---|---|---|
afftdn | ffmpeg adaptive FFT denoiser | gentle floor reduction, no ML, fastest |
rnnoise | RNNoise speech denoiser | aggressive — can gate pauses to silence |
rnnoise-mix | RNNoise blended back by voice probability | natural floor kept in pauses |
afftdn-rnnoise-mix | afftdn → RNNoise → blend the true original | steady noise tamed, floor preserved |
deepfilternet (default) | DeepFilterNet3 learned denoiser | removes hiss without over-gating |
afftdn is the classic move — a spectral-subtraction
descendant that estimates the noise spectrum and subtracts it in the frequency
domain. It only lowers the floor by a measured amount and never hard-gates, so it
is safe but mild:
# afftdn: reduce the noise floor by `nr` dB, then a safety limiter
af = f"afftdn=nr={nr}:nf={nf},alimiter=limit=0.95" # nr=12 dB, nf=-25 dBrnnoise is stronger, but on noisy material it over-suppresses — it will gate a
breath-pause into a dead, airless silence that sounds more wrong than the hiss
did. The cure is not to abandon it but to blend it back with the original.
The default, deepfilternet, is a learned full-band speech
enhancer that runs in real time on a
plain CPU. We chose it because it removes steady tape hiss far better than
afftdn without the over-gating artefacts of RNNoise — and,
critically, because it is a discriminative model, not a generative one: it
suppresses what is not voice, but it will not hallucinate
audio that was never in the recording. The same horror we engineer against in the
chat — a model inventing what was not there — has an audio twin, and we avoid it
the same way: by choosing tools that subtract rather than imagine.
The blend that keeps the room breathing
The most interesting line of code is the one that fights over-suppression. RNNoise emits, for every 10 ms frame, both the cleaned audio and a voice probability — a voice-activity-detection signal, near 1 on speech and near 0 in a pause. We use it to decide, frame by frame, how much of the original to keep.
Let be the voice probability of frame . The fraction of the original we blend back is an envelope ramped between two bounds — more original in pauses, less on voice:
and the output is the convex mix of original and processed signal:
In a pause () we keep 10% of the original, so the silence retains a faint, believable room tone instead of a vacuum. On voice () we keep 25%, so the timbre survives. The envelope is then smoothed with a Gaussian so the mix ratio never jumps frame-to-frame and creates musical noise — the warbling artefact that betrays a careless denoiser:
mix_envelope[start:end] = min_mix + (max_mix - min_mix) * voice_prob
mix_envelope = gaussian_filter1d(mix_envelope, sigma=transition_samples / 3)
mixed = mix_envelope * original_float + (1.0 - mix_envelope) * processed_floatThe afftdn-rnnoise-mix chain takes this one step further: afftdn tames the
steady noise first, RNNoise cleans the result, but the signal blended back is the
true original, not the afftdn intermediate — so the pauses get their floor from
the real recording, never from a processed copy of it.
Before and after
Here is a 30-second slice of a 1973 Śrīmad-Bhāgavatam class, with our default DeepFilterNet3 pass beneath it. In the “before”, a constant tape hiss fills every gap — the purple wash smeared across the whole upper spectrum, present even in the pauses between words. In the “after”, that wash is gone: the pauses fall to clean black, while the voice stands out crisp and loudness-normalised, and nothing of the speech is lost. That is the whole goal in one picture — the static disappears, the voice does not.
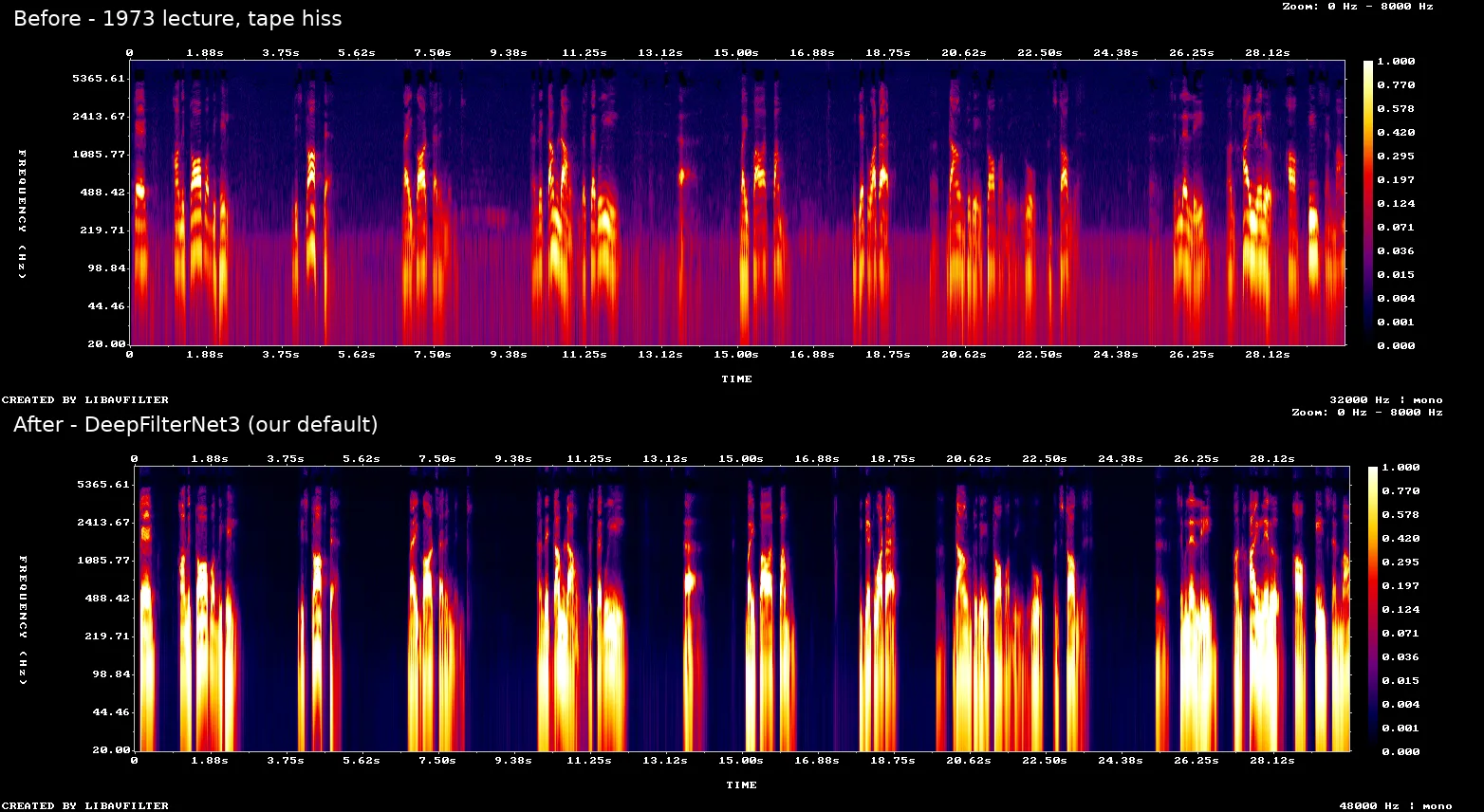
Top: the raw 1973 recording — the constant haze is tape hiss. Bottom: after DeepFilterNet3, our default. The hiss is cut to near-silence in the pauses while the voice is preserved and loudness-normalised.
Protecting the singing
A speech denoiser assumes its input is speech. Point DeepFilterNet at sung kīrtana or recited Sanskrit and it mangles them — it treats the melody as noise and scrubs it flat. An earlier draft of the corpus did exactly that, and the result was unusable.
So cleaning is not applied blindly. A splice plan marks the spans that are sung
or chanted, and routes them differently: the singing goes through gentle afftdn
(or copy — untouched) while only the spoken passages get DeepFilterNet, with a
single loudness pass stitched over the seams so the joins are inaudible. The
denoiser is told where the music is, and told to leave it alone.
Honest loudness
Old recordings are not just noisy, they are uneven — a whisper here, a shout
there. After denoising, a two-stage loudness pass evens them out without pumping:
speechnorm gently lifts quiet speech, then loudnorm hits a consistent
broadcast target across the whole corpus —
EBU R128-style, at −16 LUFS integrated with
a −1.5 dB true-peak ceiling:
NORMALIZE_FILTER = "speechnorm=e=12.5:r=0.0001:l=1,loudnorm=I=-16:TP=-1.5:LRA=11"So a listener moving from a 1972 Los Angeles lecture to a 1976 Vṛndāvana one does not lunge for the volume knob between them.
Keep the original, always
The pipeline never overwrites the source. It writes a clean track beside the original, and the app’s “original ↔ clean” slider lets the listener dial back toward the raw recording whenever they want — the same instinct as keeping the source one tap away under every translated quote. In spiritual recordings, the artefact is also a relic. The cleaned version is a convenience; the original is the thing itself, and we do not get to delete it on the listener’s behalf.
That is what “cleaning” means here. Not the most noise removed — the most voice kept.
Part of
Lectorium